
What is ElasticSearch?
Elasticsearch is an opensource search and analytics engine. It is used to analyze and process data like logs, time series data, etc.
ElasticSearch is built using Java and Apache Lucene.
ElasticSearch uses the inverted index at its core to perform search operations. An inverted index can be considered as a hashmap that maps words to the documents where those words are present.
This helps elasticsearch in quick full-text searches.
To understand how elasticsearch works, first, we need to understand its basic components and how they work.
Let’s begin with the largest component and drill down from there.
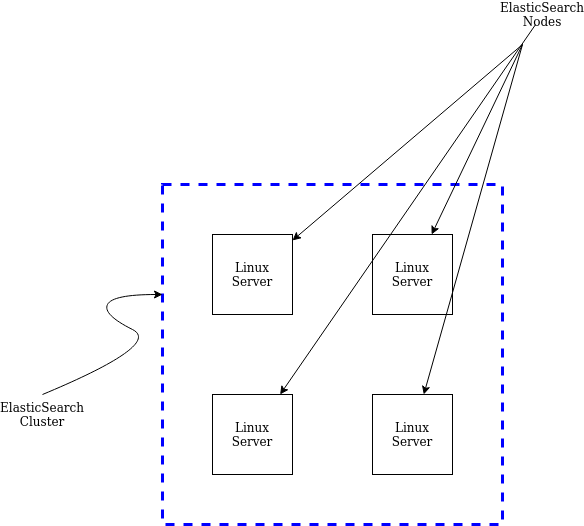
ElasticSearch Clusters
If you are running a production system, you’ll definitely have configured an elasticsearch cluster. An elasticsearch cluster is a collection of individual machines or servers.
These servers are called nodes and are responsible for hosting elasticsearch.
Nodes
Most of the time, nodes are nothing more than Linux servers running as a distributed system.
There are many different types of nodes, but the ones that we will cover in this blog, are data nodes. Data nodes store the data and do all the processing.
Within these data nodes, we have indices.
Index
An index in elasticsearch is a logical separation of data. Think of them as databases in the RDBMS ecosystem.
These are perhaps the biggest unit of logical data separation in elasticsearch. Beyond these, we move to physical isolation (like different servers – nodes)
An index is present on multiple nodes – to ensure the resiliency of data and improve the performance.
Indices are further divided into shards. This division of data into shards helps to quickly search for data in an index.
Shards
There are two types of shards
- Primary shard – an elasticsearch cluster should have 1 or more primary shards
- Replica shard – an elasticsearch cluster can have 0 or more replica shards
Primary shards hold data while replicas are just that – replicas.
The most important use of replicas is to increase the reliability of the cluster and prevent data loss. Division of data into shards should be done with proper care, as this could severely impact the performance of the entire cluster.
As a rule of thumb, primary shards and replicas are kept on different nodes, so that in case a node fails, we have its data backed up on another node. The replica then becomes the primary and a new replica shard is created on the newly added node.
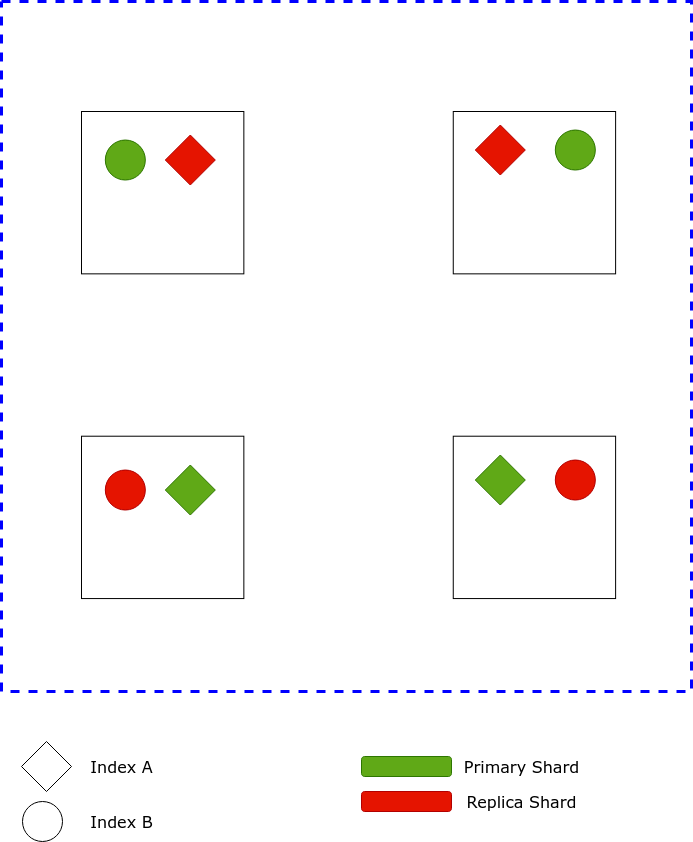
In the image above, we have two indices, with 4 shards each – two primary and two replicas.
These shards are then evenly distributed among the nodes and replicas are kept on different nodes to ensure the cluster’s reliability.
We should always try to keep the shards evenly distributed to ensure that no node is over-burdened and we are properly utilizing each node’s resources. It also helps us in planning the number of nodes to be used.
The number of shards in a replica can be set only at the time of the creation of an index. After that, we cannot modify the number of shards in an index.
Segments
Within a shard, we have segments. These are nothing more than an inverted index.
Inverted indices can be thought of as a mapping of different words and phrases to the documents where they are stored. They form the core of each search made to an elasticsearch cluster.
How does elasticsearch work with all these components?
Now that we know the basic components of elasticsearch, on a high level, how does it work?
Whenever we search for anything in the elasticsearch cluster, it first identifies the index and sends the search request to all the nodes where that index is present.
Each index then forwards the request to all of its shards which further send it to their individual segments.
The results then travel from segments to shards and finally to the index. These results are then sorted in the order of their weight and sent back as an output


