Almost everyone who has worked with DBs has heard about indexing. We often do indexing to improve the performance of our applications.
But how many of us know exactly how indexing works?
You might be wondering why you need to know how it works, right?
Because only when you know something inside out, can you use it to its full capabilities.
Before moving on to the high-level concepts, let’s take some time to go through the fundamental structure behind indexing — a B-Tree.
Though B+ Trees are also used and can provide better efficiency, we’ll stick to B-Tree as that is what is used in MS SQL Server (Our scope for this blog)
B-Tree
Most of the data structures, like arrays, stacks, linked lists, BST, etc are stored in memory (RAM)
This is why these are very fast to process, while data in files is not, as it is stored on hard disks.
So every time we need to read something from a file, we have to perform an I/O operation — which is slow.
Now we may not realize this slowness on our local computers, but when we are talking about servers serving hundreds of thousands of requests every second — they become bottlenecks.
Then why do we store data in files at all? Why not store them in memory and serve them quickly to the incoming traffic?
Well, that is because memory (RAM) is limited, you cannot have 10 TB of memory, but you can have 100TB of data.
Therefore in the case of databases, we do need to store our data on disk rather than memory.
But as we discussed, disks are slow and can therefore impact our system’s performance.
So how do we overcome this?
There is a very special class of data structures that can come to our help. These are the self-balancing trees.
These trees are designed so that after every insertion and deletion, they balance themselves such that their height is the minimum they can have.
B-Tree is a special type of self-balancing tree that is used to store large amounts of data. B+ Tree is furthermore advanced and optimized than B-Tree.
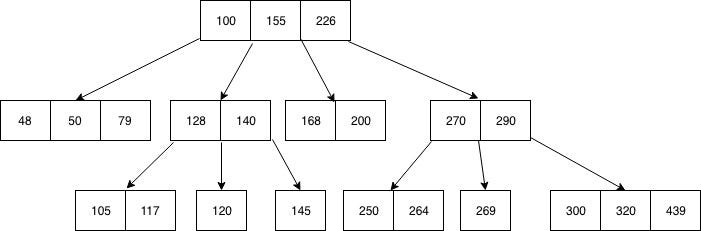
In B-Tree every node has a set of keys. Each key has two pointers leading to two other nodes — one to the left and the other to its right.
As seen in the image above, the data is stored in a sorted manner. This allows for simple and efficient traversal of the data.
But what makes this tree so much better than others? Its height!
Generally, node size is equal to that of a disk block, so that means we have only one I/O operation per node.
So even if the data is at the leaf nodes (the bottom ones), we will have very few I/O operations required to get to the data.
Why?
Because the height is minimum. Therefore the number of nodes we need to traverse to get to the very bottom of the tree is also very less. Thus, we can traverse the entire data in the minimum possible disk reads.
So even though we still need to perform disk reads (which are slow), we are performing very few of those reads now in comparison to what we would be performing if this data was stored as a heap.
Now that we know about B-Tree and how they can impact I/O performance, let’s see how they are used in SQL indexing.
Indexing
Let’s begin with a very simple definition of an index
Index is an on-disk structure associated with a table or view, which speeds the retrieval of rows of the table or view
An index contains one or more keys, called index keys. These keys are stored as a B-Tree which allows the SQL server to find rows associated with those keys quickly and efficiently.
This might be a little vague right now, so let’s consider an example.
We have a table with two columns, one is an employee ID and the other one is employee name.
Now let’s assume that we do not have indexing enabled on this table. The table has records of employees with IDs 1 to 50.
Now I need to find the name of the employee whose ID is 50. So I run the following query
SELECT name FROM employee WHERE id=50
SQL Server will now read all the rows in our table to figure out where this one particular row is. This means a lot of disk operations — which is bad!
On the other hand, if we had a B-Tree to store these IDs, and the height of the B-Tree was three, then it would have been only 3 disk read operations and we could have easily found the required record.
Now that we understand indexing a bit, let’s see the types of indexing
Clustered indexing
Clustered indexing is used to sort and store the data rows according to their key values so that they could be retrieved quickly.
Do note that I highlighted data rows above, you’ll know why soon.
These key values are the columns that are specified in the index definition — maybe we provided it or maybe the SQL server itself specified it.
But how can the SQL server itself provide the value for an index?
Whenever you create a PRIMARY KEY, a unique clustered index is created automatically if there is no clustered index already existing. See here for more details.
One more thing to note is that a table or view can have only one clustered index.
Non clustered index
The major difference between clustered and non-clustered index is the way they store data.
While clustered index stores the data row, non clustered index stores a pointer associated with each key value.
If the table has a clustered index, this pointer will point to the corresponding clustered index key. But if not, then it will point to the entire data row.
Another point worth mentioning is that if a table does not have a clustered index, then it is stored as a heap.
As we saw in the case of the clustered index, a primary key is automatically considered as a clustered index key, a UNIQUE constraint is used to automatically create a non-clustered index key.
Also, you can add columns other than the index key to the leaf nodes of the non-clustered index. These help further narrow down the number of rows.
For example, if we had city as our non-clustered index key, we might have 1000 people living in the same city.
This means that we still have to go through each of the 1000 records to find the required record.
But if we have locality added to the leaf node as well, then our search could be narrowed down to 100 people.
This in turn reduces the number of disk reads that we have to perform.
When should you not use indexing?
Till now we’ve seen why indexing is good and you might be convinced that it is the best thing to do for your performance.
But can you think of a case when we might not use indexing?
Consider for example you have a table of all your users and a column stating whether these users are active or not.
You know that for any given point in time, 90% of the users will be active.
So even though you would implement indexing, you would still need to go through 90% of the records and indexing can be overkill in these cases, which can sometimes backfire.
So as a rule of thumb, if the resulting data rows are few, we use indexing. But if we need to select a large number of data rows from the table, we might not use indexing.
Fill factor
Now that we understand completely what indexing is, it’s time to quickly go through one of the important values related to the indexing — the fill factor.
Fill factor is a value which is used to fine tune index data storage and performance
Fill factor represents how much data should a node in an index contain. For example, if we have a fill factor value of 80, then that means that only 80% of the space on each node will be filled and 20% of space in each node will be empty.
But why do we want to keep the nodes empty?
We know that B-Trees are self-balancing trees, that is every time we add something they will adjust their height so that it is minimum.
We did not think of it yet, but even the process of adjusting height takes time and can become a performance issue.
So what we do instead is leave some space in our nodes so that new data could be added there.
This avoids the addition of new nodes and since no new nodes are added, we do not need to adjust the height of the tree.
But this is only useful when the new data is inserted evenly across the tree.
In the case of our previous example of employee ID, whenever a new record is added it will be added to the end of the index since B-Tree sorts the keys and then stores them.
Therefore space in nodes will never be filled as no new data is suitable to be added there.
In this case, we are wasting space which can potentially lead to an unnecessary increase in the height of the tree and therefore reduced the I/O performance of our index.
Hence, the fill factor should be set such that we have some space in case the new records will be inserted evenly, or else if they are to be inserted at the end, we should not keep extra free space in our nodes
[hubspot portal=”21337963″ id=”56b77e0b-6e11-4a70-af5d-bc8f3168f000″ type=”form”]

