
The Linux kernel is a happening place. There are a lot of things going on within the kernel to make the entire system work.
This blog outlines some of the most important of those activities.
Processes and System Calls
Processes are activities that are responsible for running an application. Once the application is done with its execution the process can be terminated.
Creating, controlling, and terminating a process is managed by the OS kernel.
One major limitation of processes is that they run in user mode. That is, they are assigned a specific memory block and they cannot access a memory segment out of that block.
If a process tries to access a memory block outside of what has been assigned to it, an exception is raised which is handled by the kernel
But what if the process needs to get some data from other processes’ memory or access a device?
In such a scenario, a system call is raised.
System calls provide a process with complete access to the kernel address space which includes complete access to devices and memory space.
But these functions can only be performed using kernel methods – and this is another point where the kernel can put some limitations on the access.
Interrupts
Can a process be stopped (paused would be a better word) in the middle of its execution?
Yes.
This stopping of a process to be continued later can be either voluntary or involuntary to the process.
Voluntary cession is where a process itself is responsible for ceding its activity. For example, it has to read a file or wait for user input.
Involuntary cession is when a process wants to continue its work, but the kernel says, “Wait a minute!”
Why would kernel stop the execution of the process? Because of the high load on the processor?
Yes, that would be a reason – but most of the processes are paused even when we don’t have very high loads.
Then why?
The reason would be another high-priority task that needs the kernel’s attention. Interrupts are responsible for informing the kernel of such tasks.
Whenever an interrupt is received by the kernel, it will save the currently executing process’ / system call’s current state, like CPU registers, and then perform required operations to handle the interrupt.
An important mention here is the handling of these interrupts on multi-processor systems. So if we have 4 CPUs, can we have 4 interrupts running in parallel?
Yes.
But, the catch here is that even though we can have 4 separate interrupts, one on each CPU, only one of those could have its interrupt handling routine running at any given time – the rest 3 need to wait
Now that we have some basic understanding of interrupts, let’s see the types of interrupts.
Interrupts can be of two types
- Hardware interrupts
- Software interrupts
Hardware interrupts
Hardware interrupts are used by the peripheral devices to inform the kernel that there is something that needs to be taken care of right now. For example, the movement of the cursor in a mouse or pressing of a key on the keyboard.
Interrupts are characterized by an interrupt handling routine. It consists of the commands that are to be run whenever the interrupt is triggered.
The interrupt handling routine is registered at run time using request_irq() function call.
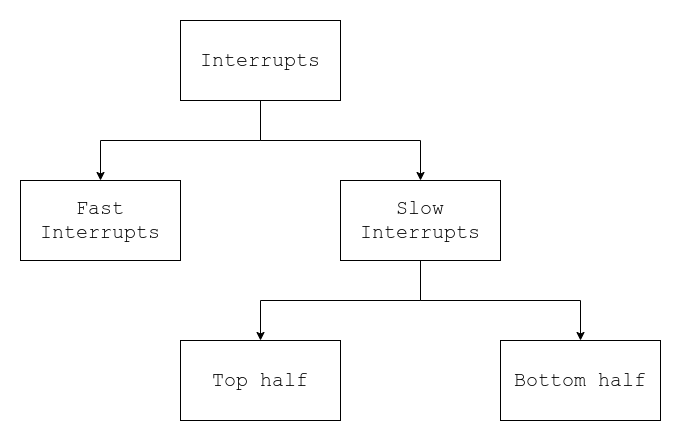
Depending on the time the interrupt handling routine takes to complete, interrupts are classified as fast interrupts and slow interrupts.
Fast interrupts are those which have slow routine completion time and therefore can be done very quickly. Generally, whenever a fast interrupt is triggered and its routing is running, no other interrupt can stop it.
Fast interrupts are designated by the SA_INTERRUPT flag when they are registered using request_irq() function call.
Slow interrupts on the other hand are those which take a lot of time to complete their routine. Stopping all the interrupts for such a long period of time would not be a good idea. Therefore, slow interrupts can be interrupted by other interrupts.
To absorb this information, let us consider a few examples.
Whenever you press a key on the keyboard, it is handled almost immediately and we can safely consider it to be a fast interrupt.
The same goes with moving the mouse cursor.
But what happens when the network adapter receives a packet?
Analyzing the packet, requesting for all the missing packets, verifying the integrity of the packet, and then passing it on to the respective processes does not happen immediately.
It takes a lot of CPU ticks to do this
This is an example of a slow interrupt. When the kernel is processing a packet and I move the cursor, it will stop the execution of packet processing and move the cursor.
See! The network interrupt was interrupted by the mouse interrupt
Consider another example, I am working on a google doc while my slack is actively receiving messages.
Now, I receive a packet, the kernel starts processing it but then I am typing, so it gives more priority to the keyboard interrupt. The packet did not get the time required to digest it and 5 more packets come in.
The kernel is now doomed!
In this scenario, the kernel will perform the bare minimum mandatory part of the processing on high priority – let’s call it the top half of the processing.
In our example, it will be adding the packet to the buffer as soon as it receives it and can then do all the other stuff in the background. This other stuff will be our bottom half.
So now when more packets are received, the kernel adds them to the buffer and goes into background processing of these packets.
In this way, although there is a delay – which is expected since it is a long process, we don’t have any packet drops just because we were processing the previous packet \( )/
In this way, we have our slow interrupts divided into two parts
- The top half
- The bottom half
Software interrupt
Software interrupts, unlike hardware interrupts, are not executed immediately. Rather they are scheduled for execution.
They are then invoked by the scheduler. A software interrupt can be run using do_softirq() function call.
A maximum of 32 software interrupts can be defined in the Linux kernel – as of writing this post.
But when exactly will a software interrupt be run?
Well, it is usually run after a system call or a hardware interrupt has completed its execution.
Most of the systems nowadays have multiple processors. In these systems, we can have software interrupts running concurrently in, one in each processor.
However, if we need to access a single piece of data on memory, the kernel manages the access using locks.
So can a software interrupt, interrupt itself?
That’ll be a weird loop – isn’t it? That’s why, no!
A software interrupt can only be interrupted by a hardware interrupt
[hubspot portal=”21337963″ id=”e955f203-596a-4933-9293-792421bb3cb6″ type=”form”]